
Share
AI voices are everywhere—your phone, your car, even your fridge might be trying to chat with you. Some sound so real that you might wonder if they're secretly human. But how does this magic happen? How do machines learn to talk like us?
Of course, technology has advanced dramatically, and that’s one reason talking machines have become so impressive. But if we look deeper, we need to ask a more fundamental question: How do machines learn and encode the building blocks of language—sounds?
Buckle up; we’re going on a ride through phonetics, spectrograms, and AI speech training!
Cracking the Code of Human Speech
There are over 6,000 languages spoken across the world, and each one has its own unique set of sounds. Every native speaker unconsciously masters these sounds, while non-native speakers often struggle with certain ones, that’s why we usually have an accent when we speak a foreign language.
The scientific study of speech sounds is called phonetics. Thanks to phonetics, we know just how many different sounds humans can produce and how languages use different combinations of them.
To put things into perspective, humans can produce around 600 different consonant sounds and 200 vowel sounds—a massive range of possibilities! But no single language uses them all. For example:
- English has about 39 sounds (24 consonants, 15 vowels).
- Ubykh, an extinct language, had a whopping 86 sounds—84 consonants and just 2 vowels!
Why the Alphabet Fails Us
The alphabet has given us a way to document human speech, but here’s the problem: it isn’t always reliable when it comes to representing pronunciation.
Take English, for instance. The same letter can sound completely different in different words.
For example:
- gym (/d͡ʒˈɪm/) vs. game (/ɡˈe͡ɪm/)
- Both start with "g," but they don’t sound the same.
- advocate as a noun vs. a verb:
- "She is an advocate" → /ˈædvəkɪt/
- "I advocate for change" → /ˈædvəkeɪt/
This isn’t just an English problem—it happens in many languages! Even languages that seem "phonetic" (where words are pronounced the way they are written) have exceptions.
So, if the alphabet isn’t enough, how do linguists accurately document sounds?
The Secret Weapon: The International Phonetic Alphabet (IPA)
Enter the International Phonetic Alphabet (IPA)! This system assigns a unique symbol to every sound human can produce, allowing us to precisely document speech sounds without ambiguity. Those odd-looking symbols I used earlier, come straight from the IPA. If you’ve ever seen weird symbols like /θ/ or /ʃ/, congratulations, you’ve met IPA!
Want to play around with weird sounds? Try this interactive chart: IPA Chart
Seeing Sound: Spectrograms
Now that we can document sounds, how do we analyze them? That’s where spectrograms come in!
A spectrogram is like an X-ray of sound. It visually represents speech by showing:
- Frequency (pitch) on the vertical axis
- Time on the horizontal axis
- Amplitude (sound energy) as varying shades of darkness or color
And here’s where it gets even cooler—within a spectrogram, we can see something called formants.
Formants: The DNA of Speech
One of the key features visible in a spectrogram is formants—concentrations of acoustic energy at specific frequencies in the speech wave. Multiple formants exist, each occurring at different frequencies, typically spaced around every 1,000 Hz. Each sound has a unique set of formants, and this is how we distinguish them from one another.
Let’s discover some examples of American English vowels’ spectrograms:
According to linguist Peter Ladefoged (2006), vowels typically have three main formants:
- F1 (related to vowel height)
- F2 (related to how far forward or back the tongue is)
- F3 (which can affect things like rounding)
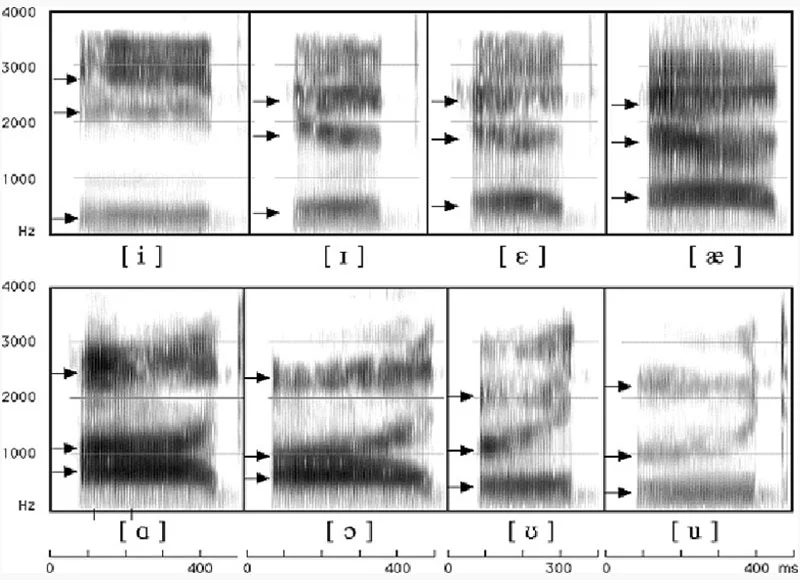
Figure 1: The Education University of Hong Kong, n.d.
If you look at a spectrogram of vowels, you’ll notice these dark bands—the formants in action!
Every IPA symbol represents a unique spectrogram and formant values of the human sounds.
Teaching Machines to Speak Like Humans
Now, here’s the million-dollar question: How do we get AI to learn and mimic human speech?
When training a text-to-speech (TTS) model, we provide it with two essential pieces of information:
- Recordings of real human speech, packed with all the necessary spectrogram and formant data.
- IPA transcriptions contain the "blueprint" of how each sound should be pronounced.
It’s like giving AI a key and a value for each sound—mapping acoustic features to symbols. By analyzing these patterns, AI learns the characteristics of different sounds and begins to mimic their spectrogram values.
The Human Brain vs. AI
Here’s something fascinating that humans do this instinctively! Our brains are wired to recognize the formant patterns of our native language(s), which is why we instantly notice when someone has an accent. Their formats don’t match what we expect!
So, the moment someone deviates (say, a French speaker trying to say “this thing” but pronouncing it as “zis sing”), we instantly detect the accent.
Next time you listen to a TTS voice, you’ll know exactly what’s happening behind the scenes. It’s a carefully trained system that has learned to "read" and "speak" by analyzing human sounds.
Listen with a Fresh Perspective!
Now that you know how AI learns to talk, click here to try out our Knovvu Text-to-Speech (TTS) voices and see if you can hear their phonetic tricks in action!
Author: Beyza Nur Hıdır, Linguist & Voice Project Specialist



