
Share
Artık yapay zekayla üretilen sesler her yerde—telefonunuzda, arabanızda, hatta buzdolabınız bile sizinle sohbet etmeye çalışıyor olabilir. Bazıları o kadar gerçekçi ki, acaba gerçek bir insan mı konuşuyor diye düşündüğünüz olmuştur. Peki, bu nasıl mümkün oldu? Makineler bizim gibi konuşmayı nasıl öğreniyor?
İlk olarak teknoloji büyük bir ilerleme kaydetti ve bu konuşan makinelerin bu kadar etkileyici hale gelmesinin önemli bir nedeni. Ancak derine indiğimizde, aslında daha temel bir soruyu sormamız gerekiyor: Makineler dili oluşturan temel yapı taşlarını—sesleri—nasıl öğreniyor ve kodluyor?
Hazır olun, çünkü sizi fonetik, spektrogramlar ve yapay zeka ses eğitimiyle dolu bir yolculuğa çıkarıyoruz!
İnsan Dilini Anlamak
Dünya genelinde 6.000’den fazla (beklentinizin üzerinde değil mi?) dil konuşuluyor ve her biri kendine özgü bir ses sistemine sahip. Anadilini konuşan biri, bu sesleri farkında olmadan kusursuzca öğrenirken, aynı dili ikinci yabancı dil olarak öğrenen biri genellikle belirli sesleri çıkarmakta zorlanır. Hatta tam da bu yüzden bir dili sonradan öğrenirken aksanımız olur. Peki yapay zeka bu kadar çok ses arasından kullandığı dile uygun olanları nasıl bulup çıkarıyor?
Dillerin seslerinin oluşumunu ve söyleniş biçimlerini inceleyen bilim dalına fonetik diyoruz. Fonetik sayesinde insanların kaç farklı sesi üretebildiğini ve dillerin bunları nasıl farklı şekillerde kullandığını öğrenebildik.
Büyük resme bakmak gerekirse: İnsanlar yaklaşık 600 farklı ünsüz ve 200 ünlü sesi üretebilir—oldukça geniş bir yelpaze! Ancak hiçbir dil bunların hepsini kullanmaz. Örneğin:
- İngilizce’de yaklaşık 39 ses bulunur (24 ünsüz, 15 ünlü).
- Artık konuşulmayan Ubykh dili ise tam 86 ses içeriyordu—84 ünsüz ve sadece 2 ünlü!
Neden Alfabe Bize Yetmiyor?
Alfabe, konuşma dilini yazıya dökmemizi belli oranda sağladı, ancak bir sorun var: Telaffuzu tam olarak yansıtamıyor. Bunu yukarıda bahsettiğim İngilizce’de 39 farklı ses olması bilgisinden de çıkarabilirsiniz, çünkü alfabede bildiğiniz üzere sadece 26 harf var. Bu durum aslında alfabenin tam doğru bir temsil yapamadığını bize gösteriyor ve sadece İngilizce’ye özgü değil. Türkçe’de de 45 farklı ses varken alfabemizde 29 harf bulunuyor!
Alfabenin çıkarabileceği bir diğer soruna örnek vermek gerekirse, İngilizce’de aynı harf farklı kelimelerde tamamen farklı seslere sahip olabilir:
- gym (/d͡ʒˈɪm/) ve game (/ɡˈe͡ɪm/)
- Her ikisi de “g” harfiyle başlıyor ama sesleri farklı.
- advocate kelimesi isim olarak farklı, fiil olarak farklı telaffuz edilir:
- "She is an advocate." → /ˈædvəkɪt/
- "I advocate for change." → /ˈædvəkeɪt/
Bu sadece İngilizce’ye özgü bir durum değil! “Okunduğu gibi yazılan” dillerde bile istisnalar bulunur.
Peki, alfabe yetersizse, dilbilimciler sesleri nasıl doğru bir şekilde kaydediyor?
Uluslararası Fonetik Alfabe (IPA)
İşte karşınızda Uluslararası Fonetik Alfabe (IPA)! Bu sistem, insanların üretebildiği her sese özel bir sembol atayarak konuşma seslerini belirsizlik olmadan belgelememizi sağlar. Yukarıda kullandığımız tuhaf görünen sembollere şaşırdınız mı? İşte onlar IPA’dan geliyor! Eğer bir yerlerde /θ/ veya /ʃ/ gibi semboller gördüyseniz, IPA ile tanışmışsınız demektir.
Farklı seslerle denemeler yapmak ister misiniz? IPA Tablosunda bir keşfe çıkabilirsiniz.
Sesi Görselleştirmek: Spektrogramlar
Peki, sesleri belgeledikten sonra nasıl analiz ediyoruz? Burada devreye spektrogramlar giriyor.
Spektrogram, sesi röntgen gibi görselleştiren bir araçtır ve sesle ilgili bize aşağıdaki bilgileri verir:
- Frekans (perde) → dikey eksen
- Zaman → yatay eksen
- Şiddet (ses enerjisi) → gölgelendirme veya renk yoğunluğu
Ve işin en ilginç kısmı: Spektrogramlarda formantlar adı verilen sesin DNA’sını oluşturan ögeleri görebiliriz.
Formantlar: Sesin DNA’sı
Bir spektrogramda görebileceğiniz en önemli özelliklerden biri formantlardır. Bunlar, konuşma dalgasında belirli frekanslarda yoğunlaşan akustik enerjilerdir.
Şimdi aşağıdaki görselde Amerikan İngilizcesi’ndeki ünlülere bakarak formantları incelemenizi istiyorum.
Dilbilimci Peter Ladefoged’e (2006) göre, ünlü sesler tipik olarak üç ana formanta sahiptir:
- F1 → Ünlünün ne kadar açık ya da kapalı olduğunu belirler.
- F2 → Dilin ne kadar önde ya da geride konumlandığını gösterir.
- F3 → Dudak yuvarlaklığı gibi ek özellikleri etkileyebilir.
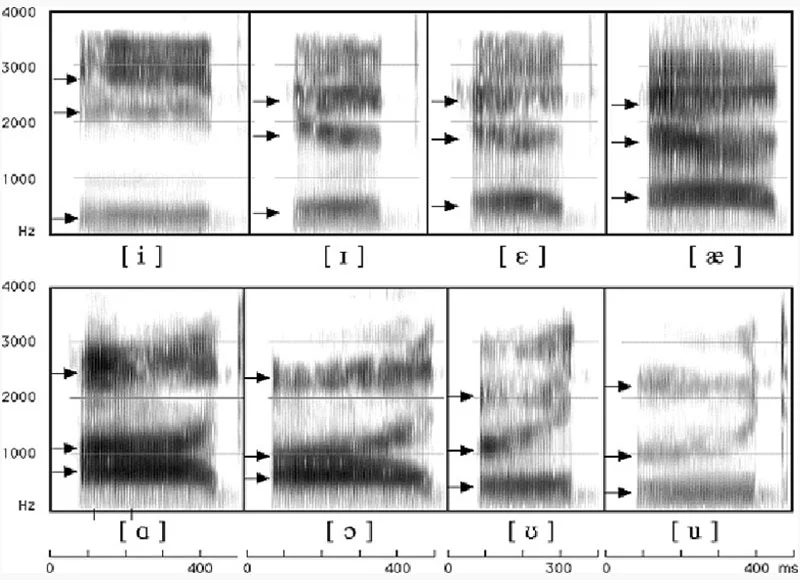
Figure 1: The Education University of Hong Kong, n.d.
Bu ünlü seslerin spektrogramlarına baktığınızda, koyu şeritleri fark edeceksiniz. Bunlar formantlardır. Altlarında da köşeli parantez içinde seslerin IPA sembollerini görebilirsiniz.
Her IPA sembolü, insan seslerinin belirli bir spektrogram ve formant değerlerine sahip olduğu bilgisini içerir.
Makinelere Konuşmayı Öğretmek
Peki, asıl soru şu: Yapay zeka insan konuşmasını nasıl öğreniyor ve taklit ediyor?
Bir Text-to-speech (TTS) modelini eğitirken iki temel veri sağlarız:
- Gerçek insan konuşması kayıtları, ki bunlar tüm spektrogram ve formantları barındırır.
- IPA transkripsiyonları, bu sesleri dokümante edip her bir sesin spektogramına bir simge atamamıza yardımcı olur.
Bu, yapay zekaya her ses için bir anahtar ve bir değer vermek gibidir—akustik özellikleri sembollerle eşleştiririz. Yapay zeka, bu kalıpları analiz ederek seslerin karakteristik özelliklerini öğrenir ve onların spektrogram değerlerini taklit etmeye başlar.
İnsan Beyni vs. Yapay Zeka
İşin ilginç kısmı şu ki insanlar bunu sezgisel olarak yapıyor. Beynimiz, ana dilimizdeki formant kalıplarını tanıyacak şekilde programlanmıştır. İşte bu yüzden birinin aksanı olup olmadığını anında fark ederiz—çünkü formantları beklentilerimizle uyuşmaz.
Örneğin, bir Fransız’ın “this thing” yerine “zis sing” demesi gibi. Beynimiz anında farkı yakalar.
Bir dahaki sefere bir TTS sesi dinlediğinizde, arka planda neler olup bittiğini artık biliyor olacaksınız.
Yeni Bir Bakış Açısıyla Dinleyin!
Artık yapay zekanın konuşmayı nasıl öğrendiğini biliyorsunuz. Şimdi bu yeni bilgilerle Knovvu Text-to-speech (TTS) seslerimizi denemek için tıklayın.
Yazar: Beyza Nur Hıdır, Linguist & Voice Project Specialist



